Python 到底是 pass by value 還是 pass by reference? 一次搞懂程式語言的函式傳參!

近日在思考 C++ 的指標問題時,意外翻到去年我在 SegmentFault 上給網友的一篇回答, 裡面詳細地討論了關於函數傳參的問題,覺得應該有不少參考價值,看完應該能夠對各種函數傳參方式有一點領悟, 故整理於此,希望能對大家有所幫助。
原本的問題
該網友有一段程式碼如下:
class Count:
def __init__(self, count=0):
self.count = count
def increment(c, times):
c.count += 1
print('c:', c.count)
times += 1
print('t:', times)
def main():
c = Count()
times = 0
for i in range(100):
increment(c, times)
main()
其執行結果為:
c: 97
t: 1
c: 98
t: 1
c: 99
t: 1
c: 100
t: 1
他不明白為何在 main 的 for 迴圈中,t 的值不會變化。
這個問題可能只是一個新手會迷惘的問題,但值得討論的地方頗多。 我發現在回答這個問題時,網友們對於 Python 使用的傳參機制有相當多的誤解,包括:
- 認為 Python 是 pass by value 或是 pass by reference (你也這樣想嗎?那我建議你看下去!)
- 認為 Python 會根據所傳入物件是可變還是不可變的去選擇使用 pass by value 和 pass by reference (這下扯更遠了)
- 想要使用 built-in function
id來做佐證,但沒有搞清楚id問的是誰的 id
若你想知道這一切問題的答案,就讓我們耐心慢慢看下去...
(1) 從 variable 跟 value 談起
這是一個很重要的概念, variable 與其 儲存(參考)的 value (object) 是兩個完全不同的東西:
variable 是一個抽象的概念,value 是一個實際存在的資料
variable 不是其對應的 value,vairable 儲存(參考)其對應的 value
舉個例子:
a = 5
我們說 a 是一個 variable, 他參考到 5 這個整數, a 不是 5, 5 不是 a,
那究竟 variable a 是什麼呢?
我們可以把他想成一個 box (在 c/c++ 中這樣的想像比較妥當), 他 儲存 著 value, 又或者我們可以把他想像成一個標籤(在 python 中可以這樣想像), 他 參考 到對應的 value。
variable 跟 value 是兩回事, 但他們有 指涉關係
(2) 關於 buildin function id
id 常常會有直覺上的誤解, 因為我們常常會使用 variable 作為 id 的 argument:
>>> a = 5
>>> id(a)
140035495798656
>>> a = 6
>>> id(a)
140035495798688
>>> id(5)
140035495798656
>>> id(6)
140035495798688
但從上面的例子可以看出來, 當我們使用 id(a) 的時候, 我們詢問的不是 a 的 id,
而是 a 對應到的 value 5 的 id, 這也是為什麼當 a = 6 的 assign 發生之後, id(a) 的結果不同了。
id問的是 value 的 id 不是 variable 的 id
(3) variable assignment 與 data manipulating
(3) 這個標題中提到兩種不同的動作(這是我自己亂叫的, 並非專有名詞, 慎之):
variable assignment 指的是變數的指派跟重新繫結:
>>> a = []
>>> id(a)
140035460871496
>>> a = [1, 2, 3]
>>> id(a)
140035460871560
上面我們讓 a 這個 variable 指涉到另外一個 list, 原本的 empty list 並沒有被動到,
a 對應的內容之所以改變, 是因為我們讓他參考到了別的 data。
data manipulating 指的是 data 本身進行了一些操作, 例如:
>>> a = []
>>> id(a)
140035460871496
>>> a.extend([1, 2, 3])
>>> id(a)
140035460871496
這種操作會使得 value(data) 的內容被改變, 但是 variable 還是指涉到同一個 data。
P.S. 關於這兩種概念的討論和注意事項請見 SegmentFault 網站該問題的 評論 處, 我與網友 chaneyzorn 的討論。
(4) 函數調用時的傳遞方式
其實整個 function call 的 pass way 只是 求值策略 Evaluation strateg 的一部分, 但我們今天重點就放在 function call 上面。
最常見的傳遞方式有三種:
- pass by value
- pass by reference
- pass by sharing (call by object reference)
我們一種一種來分析:
pass by value
此種傳遞方式會在函數內另起一個新的 variable, 並將 caller 傳入的 argument value 複製一份傳入, 此新 variable 將會指涉到這個複製的 value, 這個行為牽涉到兩個不同的 variable, 而行為上是傳遞 value 本身, 所以叫做 pass by value。
想像: 在被呼叫的函數中製造一個新的 box, 並將 caller box 中的內容 copy 一份存到新的 box 中
舉個 c++ 的例子:
void foo(int a) {
a = 6;
return;
}
int main() {
int a = 1;
foo(a);
return 0;
}
此處, main 中的 a 和 foo 中的 a 是兩個完全不同的 variable,
所以當我們進行 variable assignment (a = b) 的時候, 外面的 a 完全不會受到影響。
同樣地, 因為 value 也是複製的, 如果我們進行 data manipulating 也完全不會影響到函數以外的世界。
對兩種操作的影響: 不論在 function 中進行 variable assignment 或是 data manipulating 都不會影響外界。
pass by reference
此種傳遞方式並不一定會在函數內另起一個新 variable (要看語言), 但是 caller 中的 argument value 一定不會被複製。這種傳遞方式通常是被 特殊的語法 或是 模擬方法 所實現。
比如說, 在 c++ 中, 預設的傳遞方法是 call by value, 但他提供了特殊的參照語法讓我們得以實現 pass by referece, 我們看一個例子:
void foo(int& a) {
a = 6;
return;
}
int main() {
int a = 1;
foo(a);
return 0;
}
在這個例子中, foo 中的 a 與 main 中的 a 是同一個 variable, 如果這邊是一個 object 而不是整數,
我們也能看見這個 a 指涉到一樣的 value (這是當然的, 因為這邊根本就只有一個 variable a)。
另外像是 c, 預設的傳遞方法也是 call by value, 我們得利用指標來模擬 pass by referece, 見下例 (出自 wiki):
void modify(int p, int* q, int* r) {
p = 27; // passed by value: only the local parameter is modified
*q = 27; // passed by value or reference, check call site to determine which
*r = 27; // passed by value or reference, check call site to determine which
}
int main() {
int a = 1;
int b = 1;
int x = 1;
int* c = &x;
// a is passed by value
// b is passed by reference by creating a pointer
// c is a pointer passed by value
// b and x are changed
modify(a, &b, c);
return 0;
}
這個例子展示了 c 中完整的 pass 方法, a 是個整數, 使用 call by value 的方式傳遞,
p 是一個全新的 variable, 於是我們對此 variable 重新指派不影響外面的 a 指涉的值。
b 的傳遞透過指標來進行,此處的 q 雖然是全新的 variable,
但是 *q 卻是指涉到原本的值且對 *q 的重指派等若對於 b 的重指派,
若此處 b 為一個 object, 我們在 modify 中對 *q 指涉到的 object 作 data manipulating 一樣會影響到外面 b 指涉到的 o
x 跟 c 的部分就請大家自行參考, 不再多言。
這種藉由 pointer (address) 來模擬 pass by reference 的方法也被稱為 pass by address。
想像: 將 caller box 和其中的內容直接傳遞到 function
對兩種操作的影響: 不論在 function 中進行 variable assignment 或是 data manipulating 都會影響外界。
pass by sharing
有人把這種傳遞方式稱作 pass by object reference, 但在 wiki 中是被叫做 call by sharing, 此方式由 Barbara Liskov 命名, 並被 Python、Java(物件類型)、JavaScript、Scheme、OCaml 等語言使用。
此方式會在函數中製造一個新的 variable, 但是傳入的 value 卻不會複製, 而是讓裡面的新 variable 指涉到一樣的 value (data)。
想像: 在被呼叫的函數中製造一個新的 box, 但不複製 caller box 中的內容, 而是裝載同一份內容
請看以下例子:
def foo(lst):
lst.append(1)
lst = [2]
m = []
foo(m)
print(m)
你覺得 print(m) 的結果是什麼呢? 答案是 [1], 原因很簡單,
foo 中的 lst 一開始指涉到外面傳入的 empty list, 所以當我們 lst.appedn(1) 時,
lst 參考到的 list 跟外面的 m 參考到的 list 都被更動為 [1], 但 lst = [2] 卻不會影響外界,
因為 lst 和 m 是兩個不同的 variable, 我們只是將 lst 重新指派到一個新的 list 而已。
對兩種操作的影響: 在 function 中進行 variable assignment 的時候不會影響外界, 但是作 data manipulating 會影響外界。
(5) 回頭看本題
所以 python 並不會因為 data 是可變還是不可變的因素去決定是傳值還是傳參 (很多人都有這種誤解), 因為他都不是, 他自有其特殊的傳遞方式:
class Count:
def __init__(self, count=0):
self.count = count
def increment(c, times):
c.count += 1
# print('c:', c.count)
print('c:', id(c))
times += 1
# print('t:', times)
print('t:', id(times))
if __name__ == '__main__':
c = Count()
times = 0
print('times:', id(times))
for i in range(100):
increment(c, times)
之所以 c.count 改變而 times 不變, 並非因為 c 是傳參, times 傳值, 而是對於 pass by sharing 來說,
以 argument c 的角度而言, c.count += 1 是一個 data manipulating 的動作,
我們操作了與外界同一份 data 所以影響了外面的 c,
而 times += 1 以 argument times 的角度而言 是一個 variable assignment 的動作,
我們操作了與外界不同一個的 variable, 所以不會影響外面。
我們來看一下上面的實驗, 在外面的 id(times) 問的是 0 的 id, 而在 increment 中問的都是 1 的 id,
所以才會第一個 id(times) 與剩下來的 id(times) 不同, 但剩下來的 id(times) 皆相同。
卻不是因為外面的 times 跟裡面的 times 是不一樣的 variable 所以才會這樣的, 這裡的 times 沒有傳值,
而是共享值。
要怎麼突破這個盲點呢? 可以加上一行來測試:
def increment(c, times):
print('t begin:', id(times))
c.count += 1
...
結果:
times: 140303106782944
t begin: 140303106782944
c: 140303062368832
t: 140303106782976
t begin: 140303106782944
c: 140303062368832
t: 140303106782976
t begin: 140303106782944
c: 140303062368832
t: 140303106782976
t begin: 140303106782944
你會發現 times 跟 t begin 一樣, 值沒有被複製, 至於 t 為何最後變了,
那是因為 times += 1 讓 times 指到別人了。
(6) 結論
先用表格幫大家總結一下三種常見的傳參方式:
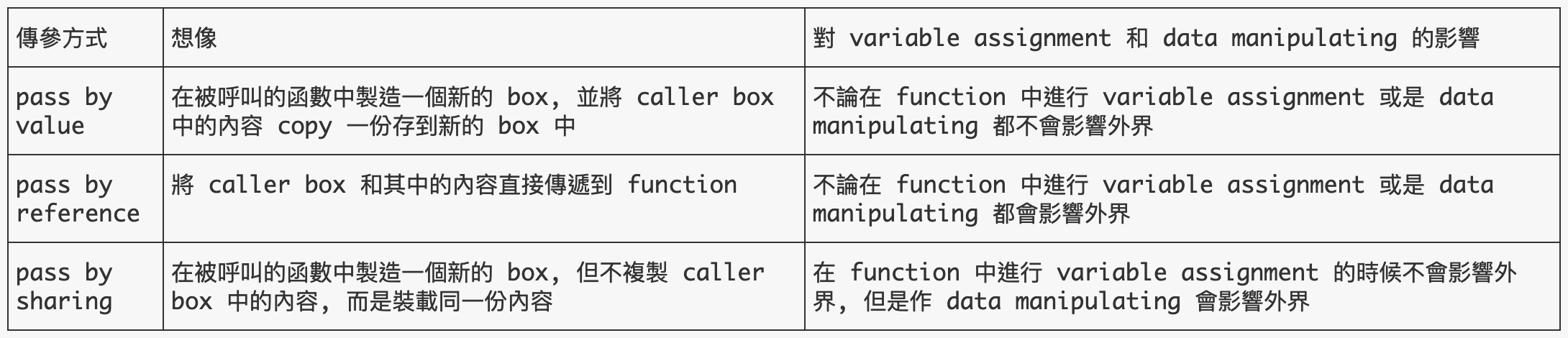
最後我們來對 Python 的傳值方式下個結論:別再說 python 是 pass by value 或是 pass by reference 了, 都不是!! python 是完完全全的 call by sharing!
(7) 參考資料
如果有興趣了解我曾經回答過的問題可以看我的 github 專案: Python-QA


